云原生成本优化实践
在全行业上云的进程中,最大的赢家可谓是公有云厂商,随着云原生越来越火,越来越多的企业也意识到使用云原生的优势:不再关注下沉的基础设施,更敏捷地实现组织转型、产品迭代、应用交付效率。虽然各行业也开始关注上云成本,但是鲜有具体的实践案例,主要有几个原因,对于大厂来说,资源不是问题,根本不用关注这个问题;对于小厂来说,研发支出和研发绩效不挂钩,业务压力那么大,为何要花时间去考虑云的成本,压缩云上资源甚至可能牺牲 SLA,而且还需要跟产品、市场跨部门沟通,很多时候还需要研发资源,财务或者老板也不懂技术,不知道这里面有多少浪费和可优化的空间,所以没有人去做这件吃力不讨好的事情。
我看了一些关于云上如何降本的文章,都是大方向,没有任何落地的实战,近期我们做了大量的优化,降低了 30%+ 左右的云计算成本,下面从我们的实战中,具体分享我们落地层面的一些行动。
在优化前,我们每月的云服务成本构成图大概是这样的: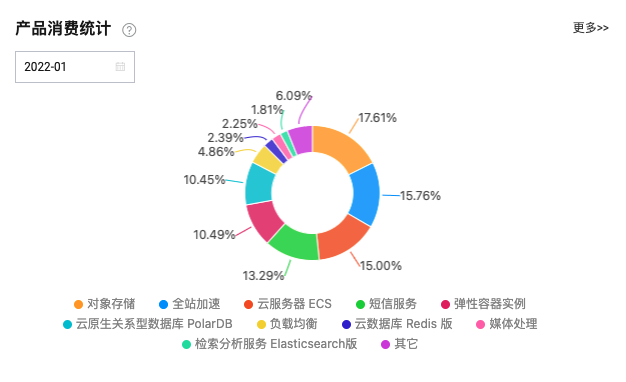
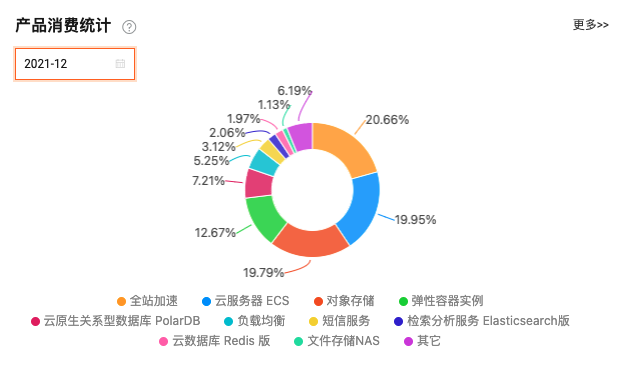 因为有特殊的运营需求,我们忽略掉 1 月份的短信服务。从这两个月的成本构成上可以看出,我们支出的大头在 OSS、CDN、ECS、ECI、PolarDB 这几块,所以,要优化云成本,我们从这几块入手,更容易看到成果。
因为有特殊的运营需求,我们忽略掉 1 月份的短信服务。从这两个月的成本构成上可以看出,我们支出的大头在 OSS、CDN、ECS、ECI、PolarDB 这几块,所以,要优化云成本,我们从这几块入手,更容易看到成果。
OSS
因为业务特殊性,我们产品有大量的图片和视频上传,目前 OSS 的规模在近 300T 左右。OSS 费用主要是三部分:存储费用、CDN回源流量费用和图片处理费用。
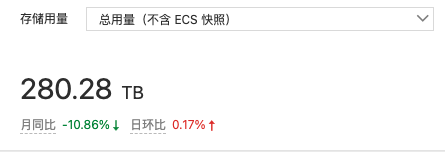
降低存储费用的直接方式就是在可接受的范围内减少存储的容量,因为业务特殊性,销售付费转化和上传的媒体数量是有正相关性的,所以产品和运营侧会不断促使用户上传更多的内容,所以不可能限制用户上传的数量,那优化上传后的文件大小是一个容易想到的方向。因为近几年视频内容的流行,用户上传视频内容的比例在不断增加,虽然客户端在上传视频前做了一步压缩处理,但是这个压缩是有限和耗时的,所以上传上来的视频仍然会比较大。我们之前是没有对这一块做特殊处理的。
这次我们使用阿里云的媒体处理功能,通过设置工作流和管道,每一个上传到 OSS 的视频会自动触发转码,用阿里云的窄带高清转码出来的效果对用户来说在手机上感知到的差别非常小,但实际的文件大小约为原始大小的 1/5 - 1/10,这里通过增加一次性的媒体处理费用,来换长期需要付费的存储空间费用,是非常划算的。 另外,根据业务场景,对已经不在使用产品的用户的媒体内容,进行定期的压缩,压缩后满足用户回归再查看时不受影响无感知即可。
CDN
CDN 主要的费用就是流量费,那优化的方向也很明确,那就是降低流量。从技术角度来说,能做的几个方向是:
- 客户端每次加载的图片资源根据展示容器大小按需加载对应尺寸的图片,通过 OSS 的图片处理参数,拼接对应的宽高,而非加载原图。这个是最基础的,不仅是节省流量的大头,也可以大大提升客户端图片的加载速度,提升用户体验。
- 在上述宽高的基础上,增加 OSS 图片处理支持的其他参数,比如格式使用 webp ,用户几乎无感知,图片大小可以减少 20% - 50% 左右。比如图片质量设置为 80%,用户也几乎无感知,图片大小可以再减少 50% 左右。这两个参数可以让整体的图片大小减少到之前的 30% 左右,换算为 CDN 成本就是 70% 实实在在的降低,而对于用户来说,体验不降反增。
ECS
ECS 在我们的场景主要是 kubernetes 集群的节点,节点数和 kubernetes 容器规模是相关的,所以优化 ECS 的根本是在优化每一个 deployment 的配置和弹性伸缩的配置。
kubernetes 看一个节点是否能调度更多的 pod ,统计的指标依据是 requests,我们每一个 deployment 的 resources 设置原则一般是 limits = request * 2,hpa 设置的扩容阈值是达到 requests 的 100% 的时候(当然也有特殊的情况),这样,当一个 deployment 的所有 pod requests 均值到 100% 的时候会自动触发扩容,这在我们实践下来是一个安全且资源利用率最高的规则,在 SLA 和成本之间找到了一个非常好的平衡点。
ECI
ECI 的使用我们踩了不少坑,花了不少冤枉钱,其中最大的坑在于阿里云默认对于不设置 resources 的 pod 会给一个默认的 2C4G 的规则,这个规格按量付费的价格是 0.44 元/小时,一天成本高达 10元左右,如果整个集群所有服务都不设置,这部分的开销可谓是非常高的,我们之前一直在优化 ECI 的费用,收获甚微,近期发现这个点以后,我们把所有 resources 都设置为 0.25C0.5G 且部分迁移到云原生服务以后,ECI 的成本降低了 70%!
PolarDB
我们从 2020 年开始将核心业务数据库从 RDS 迁移到 PolarDB,PolarDB 解决了之前 RDS 很多问题,比如只读节点扩容耗时非常长的问题,因为底层数据需要做一次完全的复制,PolarDB 因为底层数据是共享的,所以可以做到分钟级的节点扩容,这让我们在数据库计算层可以从容应对高并发高流量。但底层的支持是一部分,数据库扩容的触发条件一般是 CPU 阈值,CPU 高的主要原因一般来说是为命中索引导致的扫描行数多导致的慢查询,业务层如果优化到位的话,是可以减少底层节点扩缩容的频率的。这时合理运用阿里云 SQL 洞察功能去分析耗时占比高或者扫描行数多的 SQL,针对性地去优化一波业务查询是非常必要的。这期间我们对于索引优化、 json_contains、隐式转换等方面的优化大大降低了数据库层面的 CPU 负载,极大减少了数据库节点的扩缩容频率。
后续方向
Serveless 这两年开始逐渐升温,对于短时间的流量洪峰,Serveless 是非常合适的,不长时间占资源,可以充分享受云原生的弹性和按量,对于成本的节省是非常可观的,这将成为我们后续某些场景考虑的重点方向。